이 포스트는 Github 접속 제약이 있을 경우를 위한 것이며, 아래와 동일 내용을 관련 그림 및 실행 결과와 함께 Jupyter notebook으로도 보실 수 있습니다.
You can also see the following as Jupyter notebook along with related images and execution result screens if you have no trouble connecting to the Github.
다대일 RNN Modeling Review
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext.legacy import data, datasets
import random
from torchtext.legacy.data import TabularDataset
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
print("cpu와 cuda 중 다음 기기로 학습함:", DEVICE)
SEED = 5
random.seed(SEED)
torch.manual_seed(SEED)
7-1. Review Data 수집 및 전처리
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/LawrenceDuan/IMDb-Review-Analysis/master/IMDb_Reviews.csv", filename="IMDb_Reviews.csv")
import pandas as pd
df = pd.read_csv('IMDb_Reviews.csv', encoding='latin1')
df.head()
- 샘플 갯수 확인
print('전체 샘플의 개수 : {}'.format(len(df))) - Sample 수가 많으므로, 연산 분석용으로 대폭 줄여 새로운 파일을 만든 후 사용
df = pd.read_csv('IMDb_Reviews_test.csv', encoding='latin1') df.head() print('전체 샘플의 개수 : {}'.format(len(df)))
훈련 데이터, 평가 데이터, 테스트 데이터로 분리
train_df = df[:15]
test_df = df[15:]
train_df.to_csv("train_20_data.csv", index=False)
test_df.to_csv("test_20_data.csv", index=False)
7-2. Field 정의 및 Dataset 만들기
TEXT = data.Field(sequential=True,lower=True, batch_first=True)
LABEL = data.Field(sequential=False, batch_first=True)
trainset, testset = TabularDataset.splits(
path='.', train='train_20_data.csv', test='test_20_data.csv', format='csv',
fields=[('text', TEXT), ('label', LABEL)], skip_header=True)
- field: Data column format 정의
Dataset sample 확인
print('훈련 샘플의 개수 : {}'.format(len(trainset)))
print('테스트 샘플의 개수 : {}'.format(len(testset)))
print(trainset[0])
- trainset 내용물 확인 방법
print(vars(testset[0]))
7-3. Vocabulary set 만들기
- 단어 집합 생성, 단어 수가 적으므로 최소 횟수를 2로 설정
TEXT.build_vocab(trainset, min_freq=2)
LABEL.build_vocab(trainset)
n_vocab = len(TEXT.vocab)
print('단어 집합의 크기 : {}'.format(n_vocab))
- 수집된 전체 단어 확인
print(TEXT.vocab.stoi)
훈련 데이터와 평가 데이터 분리
trainset_2, valset = trainset.split(split_ratio=0.75)
print('훈련 샘플의 개수 : {}'.format(len(trainset_2)))
print('평가 샘플의 개수 : {}'.format(len(valset)))
7-4. Data loader
Dataloader test
BATCH_SIZE = 2
train_iter, val_iter, test_iter = data.BucketIterator.splits(
(trainset_2, valset, testset), batch_size=BATCH_SIZE,
shuffle=True, repeat=False, sort=False)
print('훈련 데이터의 미니 배치의 개수 : {}'.format(len(train_iter)))
print('검증 데이터의 미니 배치의 개수 : {}'.format(len(val_iter)))
print('테스트 데이터의 미니 배치의 개수 : {}'.format(len(test_iter)))
- shuffle 진행 안하면 Data 변환 추적 쉬움.
- data.BucketIterator.splits 조건에 sort=False를 하지 않으면 “ ‘<’ not supported … “ Error 발생
batch = next(iter(train_iter)) # Dataloader가 iterator 역할을 잘하는지 확인.
print(batch) # 재실행 때마다 sample 크기 변해야 됨.
batch2 = next(iter(val_iter))
print(batch2)
print('훈련 데이터의 샘플의 개수 재확인 : {}'.format(len(train_iter.dataset)))
print('검증 데이터의 샘플의 개수 재확인 : {}'.format(len(val_iter.dataset)))
print('테스트 데이터의 샘플의 개수 재확인 : {}'.format(len(test_iter.dataset)))
batch Iterator test
for b, batch in enumerate(train_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
print('b is {}. batch is {}'. format(b, batch)) # batch 개수 확인
for b, batch in enumerate(train_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
print('x is {}. y is {}'. format(x, y))
print('수정된 Y 값:' , y.data.sub_(1)) # lable 값 조정: y값에서 () 값을 뺌, sub 대신 add를 하면 더함
7-5. Reviewing RNN, GRU Model
- Embedding, RNN/GRU, Cost Function 동작 확인
hyperparameters
n_classes = 2 # 분류되어야 할 결과 수 (긍정 or 부정)
embed_dim= 8 # 임베딩 된 차원의 크기 : RNN 층 입력 차원의 크기가 됨
hidden_size = 6 # RNN의 은닉층 크기
Embedding Test
Emb_Test=nn.Embedding(num_embeddings=n_vocab, embedding_dim=embed_dim)
-
num_embedding는 trainset 단어 전체 갯수인 n_vocab로 지정
- 가중치 확인
print(Emb_Test.weight.shape) # (단어갯수, embedding dim) print(Emb_Test.weight) - 임베딩 결과 차원 확인 : (batch 크기 x 문장 단어 크기 x embedding 크기)
print(Emb_Test(x).shape) print(Emb_Test(x).size(0)) # batch size 출력
RNN input Test
rnn_test = nn.RNN(embed_dim, hidden_size, batch_first=True)
- model에 구성된 파라미터 가중치 확인 : 추가 분석은 아래 참고
print(rnn_test.parameters()) print(next(rnn_test.parameters()).shape) # 벡터 크기 : (hidden_size, embed_dim)
output_rnn, hidden_rnn = rnn_test (Emb_Test(x)) # Tuple 형태의 결과를 분리
print(output_rnn.shape) # (batch 크기 x 문장 길이 x 은닉층 크기)
print(hidden_rnn.shape) # (층 크기 x batch 크기 x 은닉층 크기)
GRU input Test
- 긴 문장에서는 RNN보다 GRU가 더 나은 결과를 보임
gru_test = nn.GRU(embed_dim, hidden_size, batch_first=True)
# model에 구성된 파라미터 가중치 확인 : 추가 분석은 아래 참고
print(gru_test.parameters()) # RNN과 parameter 벡터가 다름
print(next(gru_test.parameters()).shape) # (hidden_size x3 , embed_dim)
output_gru, hidden_gru = gru_test (Emb_Test(x)) # Tuple 형태의 결과를 분리
print(output_gru.shape) # 결과와 은닉 가중치 벡터 크기는 RNN과 동일
print(hidden_gru.shape)
Return Analysis
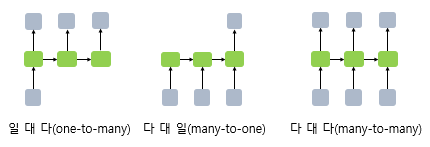
- 리뷰 감성 분류는 긍정/부정 하나의 분류이므로, RNN 다대일 구조이며, 이 경우 RNN 연산 결과는 n개 은닉 상태 중에서 마지막 번째만 선택
x_out = output_rnn[:, -1, :]
print(x_out)
dropout
dropout_p=0.3 # '0'은 dropout이 없고, '1'이면 모두 zero로 만듬
dropout = nn.Dropout(dropout_p)
x_out = dropout(x_out)
print(x_out)
Linear Regression test for Binary Selection
linear_test = nn.Linear(hidden_size, n_classes)
out=linear_test(x_out)
print(out) # (batch 크기 x 분류 갯수)
- 가중치 확인
print(linear_test.weight.shape) print(linear_test.weight)
Comparing selection results with labels
# 0과 1에서 높은 확률값 선택
print(out.max(1))
print("결과값 : ", out.max(1)[1])
print(y) # 현재 Label값들
# out값을 y차원에 맞춰 다시 정렬
print(out.max(1)[1].view(y.size()))
# out값과 Label이 맞는 갯수
print((out.max(1)[1].view(y.size()).data == y.data).sum())
Cost function Test
loss = F.cross_entropy(out, y)
print(loss)
# loss 값만 출력하는 방법
print(loss.item())
7-6. Designing Model
Simple Modeling
- 연산 순서: Embedding -> GRU (or RNN) -> binary Classification
- 긴 문장이되면 동일 하이파라미터 조건에서도 RNN보다 GRU가 우수하므로 아래는 GRU로 진행
class myModel(nn.Module):
def __init__(self, hidden_size, n_vocab, embed_dim, n_classes, dropout_p, batch_first=True):
super(myModel, self).__init__()
self.embedding_layer = nn.Embedding(num_embeddings=n_vocab, embedding_dim=embed_dim)
self.gru_layer = nn.GRU(embed_dim, hidden_size, batch_first=batch_first)
self.dropout = nn.Dropout(dropout_p)
self.linear = nn.Linear(hidden_size, n_classes)
def forward(self, x):
output = self.embedding_layer(x)
output, hidden = self.gru_layer(output)
x_out = self.dropout(output[:, -1, :])
output = self.linear(x_out)
return output
- 모델 생성
simple_model = myModel(hidden_size, n_vocab, embed_dim, n_classes, dropout_p, batch_first=True)
print(simple_model(x)) # x 입력하여 Model test
optimizer = torch.optim.Adam(params=simple_model.parameters(), lr = 0.005)
Model Training
for step in range(1, 21):
for b, batch in enumerate(train_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1) # lable 값 0 또는 1로 조정
optimizer.zero_grad()
output = simple_model(x)
loss = F.cross_entropy(output, y, reduction='sum')
loss.backward()
optimizer.step()
if step % 4 == 0:
print("[{:02d}/20] output is {}, y is {}, and loss is {:.4f} ".format(step, output.data, y, loss))
7-7. Model Evaluation
corrects, total_loss = 0, 0
for b, batch in enumerate(val_iter):
x, y = batch.text.to(DEVICE), batch.label.to(DEVICE)
y.data.sub_(1)
output = simple_model(x)
loss = F.cross_entropy(output, y, reduction='sum')
total_loss += loss.item() # loss 누적 값
corrects += (output.max(1)[1].view(y.size()).data == y.data).sum() # 정답 맞춘 총횟수
size = len(val_iter.dataset)
avg_loss = total_loss / size
avg_accuracy = 100.0 * corrects / size
print("val loss is {}, val accuracy is {}".format (avg_loss, avg_accuracy))
참고: Model의 가중치(Parameters) 분석
# Model 가중치
simple_model.parameters()
- 가중치 확인
list(simple_model.parameters()) - Model 가중치에는 총 7개 요소가 있으며, 앞서 확인한 Embedding, RNN, Linear regression 등의 가중치가 모두 포함되었음을 알 수 있다.
para = list(simple_model.parameters()) print('Embedding:', para[0].shape,'\n GRU: ', para[1].shape, '\n', para[2].shape, para[3].shape, para[4].shape, '\n Linear regression : ', para[5].shape,'\n', para[6].shape) - 가중치인 generator 동작 확인
para = next(simple_model.parameters()).data print(para.shape,para) - 가중치 차원 변형 방법
para.new(33, 5, 4) - 가중치 초기화 방법
para.new(32, 5).zero_()