이 포스트는 Github 접속 제약이 있을 경우를 위한 것이며, 아래와 동일 내용을 실행 결과와 함께 Jupyter notebook으로도 보실 수 있습니다.
You can also see the following as Jupyter notebook along with execution result screens if you have no trouble connecting to the Github.
분류 항목이 동일한 표본들이 서로 다른 특성값을 갖는 Data 정리
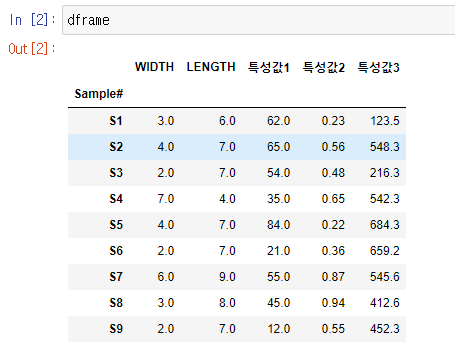
- S2, S5 와 S3, S6, S9는 각각 분류 항목 WIDTH와 LENGTH가 동일하나 서로 다른 특성값을 가지고 있음.
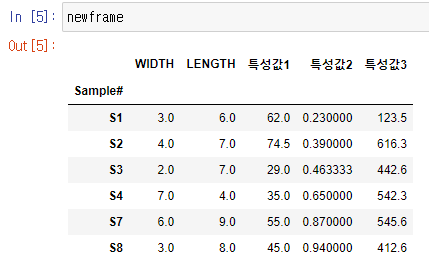
- 아래와 같이, 중복되는 항목의 첫 번째 Sample Index ‘S2, S3’를 기준으로, 각 특성값의 평균을 갖는 새로운 Dataframe을 생성하는 함수 코드
from pandas import DataFrame
def DataframeAvg(dframe, sortlist): # dframe: DataFrame, sortlist: 분류항목 List (2개)
unipair = dframe[sortlist].drop_duplicates(sortlist, keep='first')
# 분류 항목 중 중복을 제외한 값 모음
unique_pair = []
# 선택된 column에 중복을 제외한 값 List 축출
for i in range(unipair.shape[0]):
unique_pair.append([unipair.iloc[i,j] for j in range(0, unipair.shape[-1])])
# 중복없는 항목의 Dataframe을 만들기 위한 새 Dataframe 생성
newframe = DataFrame(columns=dframe.columns)
# 중복을 제외한 분류 항목 값 하나에 대해, sortlist filtering
for val in unique_pair:
sortedframe = dframe[(dframe[sortlist[0]] == val[0]) & (dframe[sortlist[1]] == val[1])]
# dataframe에서 해당 항목 값으로 filtering해서,
# 해당 항목의 각 특성값을 평균하여 추가할 신규 DataFrame 생성
# sortedframe.mean() methode 사용시, 인덱스 Sample# str 값이 제거되므로, 별도 추가 생성시켜야함
data = [sortedframe.index[0]] + list(sortedframe.mean())
col = [dframe.index.name] + list(sortedframe.mean()._index)
# row data 1개 추가를 위한 신규 DataFrame 생성
appDF = DataFrame ([data], columns = col)
newframe = newframe.append(appDF) # 평균값 data 추가
newframe = newframe.set_index(dframe.index.name) # Sample# 를 인덱스로 다시 지정
return newframe
- 함수 실행
sortlist = ['WIDTH', 'LENGTH'] # Sorting 기준 newframe= DataframeAvg(dframe, sortlist)