이 포스트는 Github 접속 제약이 있을 경우를 위한 것이며, 아래와 동일 내용을 실행 결과와 함께 Jupyter notebook으로도 보실 수 있습니다.
You can also see the following as Jupyter notebook along with execution result screens if you have no trouble connecting to the Github.
Excel 파일을 열고 Sheet별 Data 불러오기
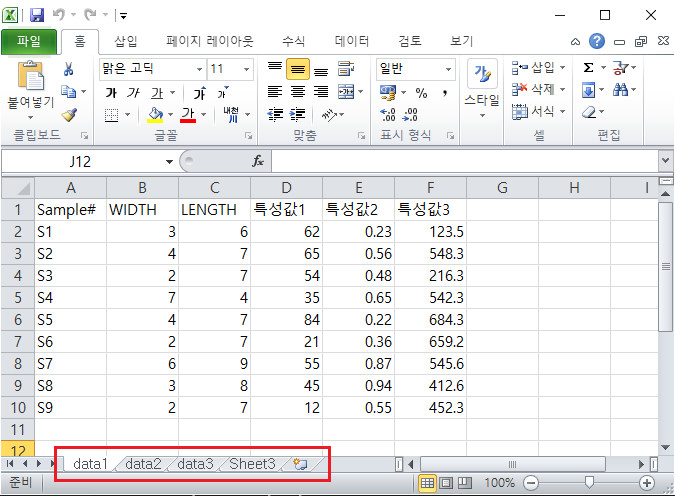
- Sheet 이름이 data1, data2, data3, Sheet3으로 총 4개가 있으며, Sheet3에는 data가 없는 상태입니다.. (편의상, 예제에서 data1~3 sheet에 있는 data는 동일합니다..)
import xlwings as xw
import pandas as pd
book = xw.Book('../test.xlsx')
n_sheet = len(book.sheets) # book에 있는 Sheet 갯수
dataframes = {} # Sheet에서 불러온 data를 모아두는 곳
for k in range(n_sheet):
key = 'data' + str(k) # Sheet별 불러온 data이름을 새로 생성
dataframes[key] = book.sheets[k].used_range.options(pd.DataFrame).value

- pandas DataFrame으로 Sheet의 Data를 불러왔고, Sheet별 Data를 Dictionary로 구별하였습니다.
- Excel Sheet 이름을 그대로 불러온 것이 아니고, for 문으로 Key이름을 자동 생성하다 보니, Data가 있던 Sheet 이름과 Dataframe의 이름이 달라졌습니다.
Dataframe들을 Excel에 저장하는 함수정의
def writeExcelSheet (book, sheetname, datatable = None):
sheetlist = [sheet.name for sheet in book.sheets] # 주어진 Book에 Sheet list 작성
if sheetname not in sheetlist:
book.sheets.add().name = sheetname # 지정한 sheetname 없으면 해당 sheet 신규 생성
# 선택된 Sheet에 Data가 있는지 확인 후, 없으면 'A1'에, 있으면 그 아래에 Data 추가
topdown = int(book.sheets[sheetname].range('A1:Z1').end('down').address.split('$')[-1])
bottomup = int(book.sheets[sheetname].range('A1048500:Z1048500').end('up').address.split('$')[-1])
if bottomup == 1: # Sheet 맨아래에서 위로 찾아올라가서 1번 행이면 빈 Sheet
sheetrange = bottomup
elif topdown <= bottomup: # Sheet 위에서 아래로, 아래에서 위로 찾아가면서 Data 발견되는지 확인
sheetrange = bottomup + 2
else: pass
book.sheets(sheetname)['A' + str(sheetrange)].value = datatable
book.save()
- 앞서 Excel 파일에서 불러왔던 Data를 writeExcelSheet를 이용해서 다시 저장해봅니다.
fpath = 'd:/mybook.xlsx'
book = xw.Book()
book.save(fpath)
for key in dataframes: # dataframes에 들어있는 data를 검색
sheetname = 'new' + key # 새로운 Sheet 이름을 생성
data = dataframes[key] # 저장할 Data를 선택
writeExcelSheet(book, sheetname, datatable = data) # Excel에 저장.
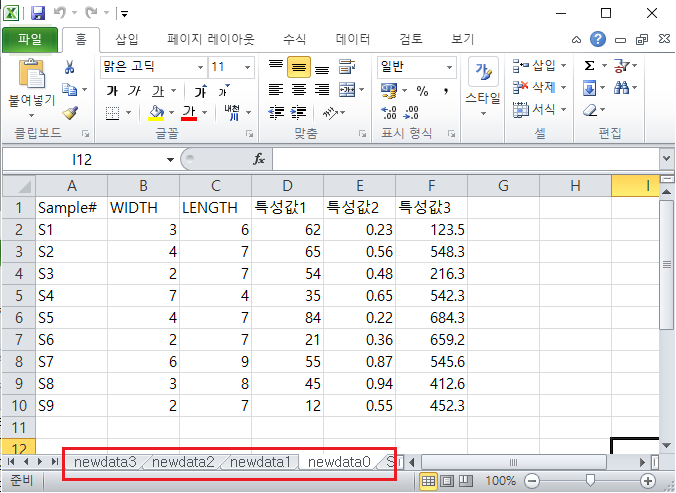
- 새로운 Excel 파일에서 새로운 Sheet이름으로 Data들이 저장된 것을 확인할 수 있습니다.